数据持久化与索引
与所有类似LSMT的存储引擎一样,MemTables中的数据被持久化到耐久性存储,例如本地磁盘文件系统或对象存储服务。GreptimeDB采用Apache Parquet作为其持久文件格式。
SST 文件格式
Parquet 是一种提供快速数据查询的开源列式存储格式,已经被许多项目采用,例如 Delta Lake。
Parquet 具有层次结构,类似于“行组-列-数据页”。Parquet 文件中的数据被水平分区为行组(row group),在其中相同列的所有值一起存储以形成数据页(data pages)。数据页是最小的存储单元。这种结构极大地提高了性能。
首先,数据按列聚集,这使得文件扫描更加高效,特别是当查询只涉及少数列时,这在分析系统中非常常见。
其次,相同列的数据往往是同质的(比如具备近似的值),这有助于在采用字典和 Run-Length Encoding(RLE)等技术进行压缩。
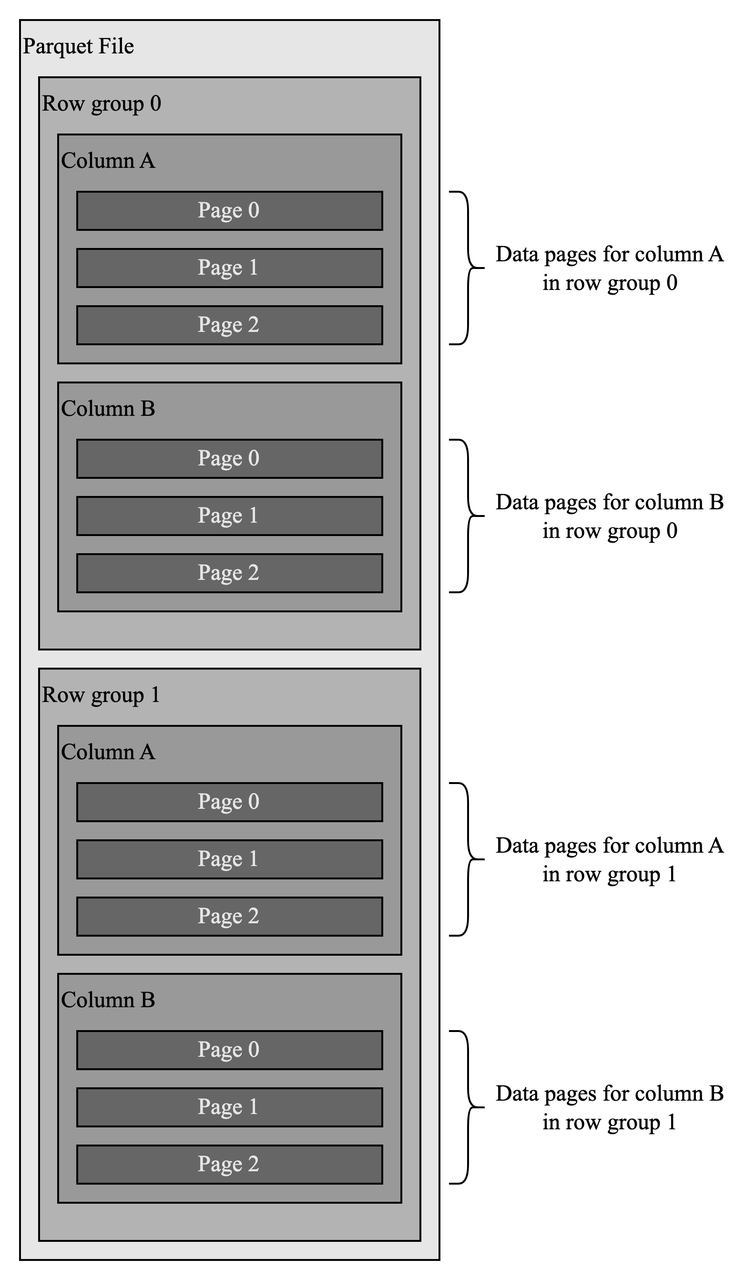
数据持久化
GreptimeDB 提供了 storage.flush.global_write_buffer_size 的配置项来设置全局的 Memtable 大小阈值。当数据库所有 MemTable 中的数据量之和达到阈值时将自动触发持久化操作,将 MemTable 的数据 flush 到 SST 文件中。
在 SST 文件的索引
Apache Parquet文件格式在列块和数据页的头部提供了内置的统计信息,用于剪枝和跳过。
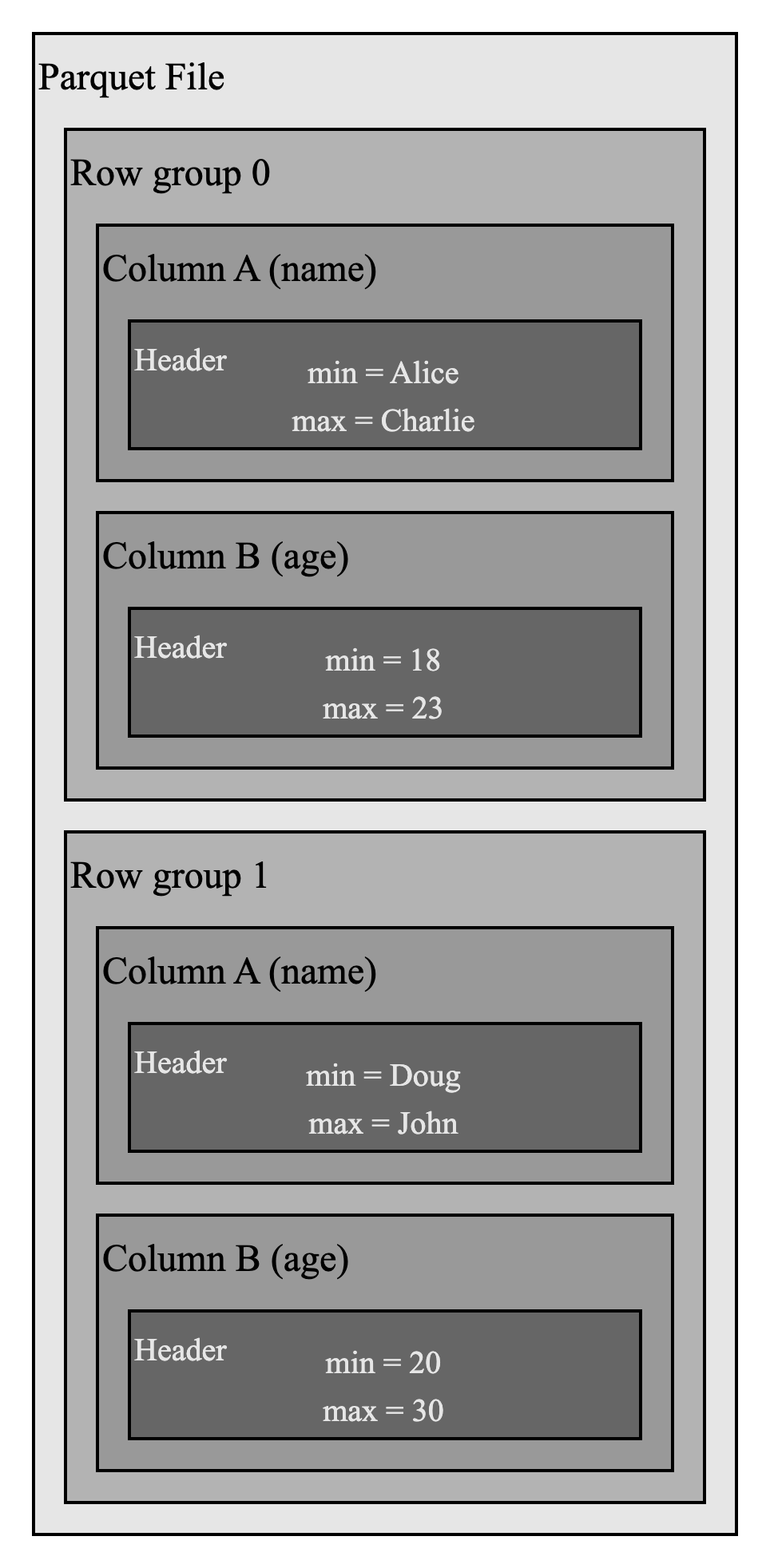
例如,在上述 Parquet 文件中,如果你想要过滤 name 等于 Emily 的行,你可以轻松跳过行组 0,因为 name 字段的最大值是 Charlie。这些统计信息减少了 IO 操作。
除了 Parquet 内置的统计信息外,我们的团队正在开发支持使用一些时间序列特定的索引技术的单独索引文件,以提高扫描性能。
统一数据访问层:OpenDAL
GreptimeDB使用 OpenDAL 提供统一的数据访问层,因此,存储引擎无需与不同的存储 API 交互,数据可以无缝迁移到基于云的存储,如AWS S3。